Github开源项目WebServer: C++ Linux WebServer服务器学习笔记
项目链接🔗 qinguoyi/TinyWebServer: :fire: Linux下C++轻量级WebServer服务器
markparticle/WebServer: C++ Linux WebServer服务器
学习资料来源于第一个,学习代码来源于第二个
书籍 《Linux高性能服务器编程 (游双 著)》
《C++并发编程实战(第2版) (安东尼·威廉姆斯)》
项目运行 环境
Linux CentOS 7 64位
g++ (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2) 默认支持C++14标准
配置数据库 MySQL安装 安装前环境检查
1 2 3 4 5 6 7 su rpm -qa | grep mysql rpm -qa | grep mysql | xargs yum -y remove ls /etc/my.cnf rm -rf /etc/my.cnf which mysql which mysqld
下载安装包
http://repo.mysql.com
1 2 3 4 cat /etc/redhat-release // CentOS Linux release 7.9.2009 (Core) yum install -y https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm yum install -y mysql-community-server
提示GPG 密钥不适合报错
1 2 3 4 5 mysql-community-libs-5.7.44-1.el7.x86_64.rpm 的公钥尚未安装 失败的软件包是:mysql-community-libs-5.7.44-1.el7.x86_64 GPG 密钥配置为:file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql
解决方法
1 2 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022 yum install -y mysql-community-server
配置 MySQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 sudo grep 'temporary password' /var/log/mysqld.logmysql -uroot -p ALTER USER 'root' @'localhost' IDENTIFIED BY 'YourNewPassword' ; sudo mysql_secure_installation按提示操作,建议移除匿名用户、禁止root用户远程登录、删除测试数据库等。 GRANT ALL PRIVILEGES ON *.* TO 'root' @'%' IDENTIFIED BY 'YourNewPassword' WITH GRANT OPTION; FLUSH PRIVILEGES; sudo firewall-cmd --permanent --zone=public --add-port=3306/tcpsudo firewall-cmd --reload
修改密码报错:Your password does not satisfy the current policy requirements
出现问题的主要原因是 MySQL 有默认的密码策略
1 SHOW VARIABLES LIKE 'validate_password%'; # 查看当前的密码策略
validate_password_policy:密码策略,默认值为MEDIUM。可以设置为LOW、MEDIUM、STRONG或者自定义。例如,可以将其设置为LOW以降低密码复杂性要求
1 SET GLOBAL validate_password_policy = LOW;
不同策略的要求
validate_password_length:密码最小长度,默认值为8。可以根据需要修改最小密码长度
1 SET GLOBAL validate_password_length = 6;
validate_password_number_count:密码中的数字要求,默认值为1。可以增加或减少数字的要求
1 SET GLOBAL validate_password_number_count = 0;
validate_password_special_char_count:密码中特殊字符的要求,默认值为1。可以增加或减少特殊字符的要求
1 SET GLOBAL validate_password_special_char_count = 0;
validate_password_mixed_case_count:密码中大写字母和小写字母的要求,默认值为1。可以增加或减少大写字母和小写字母的要求
1 SET GLOBAL validate_password_mixed_case_count = 0;
修改 MySQL 配置文件(通常是 mysqld.cnf 或 my.cnf)以使修改的密码策略永久生效
1 2 3 4 5 validate_password_policy=LOW validate_password_length=6 validate_password_number_count=0 validate_password_special_char_count=0 validate_password_mixed_case_count=0
重启 MySQL 服务以应用更改
执行 MySQL 服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 systemctl status mysql.service systemctl start mysqld.service systemctl stop mysqld.service systemctl restart mysqld.service systemctl enable mysqld.service mysql -uroot -p
配置数据库 1 2 3 4 5 6 7 8 9 10 11 12 # 建立 tinyWebServer 库 create database tinyWebServer; # 创建user表 USE tinyWebServer; CREATE TABLE user( username char(50) NULL, password char(50) NULL )ENGINE=InnoDB; # 添加数据 INSERT INTO user(username, password) VALUES('name', 'password');
运行项目 1.从GitHub下载源代码,运行服务器
报错 fatal error: mysql/mysql.h: 没有那个文件或目录 #include <mysql/mysql.h>
1 2 3 4 5 6 sudo yum install mysql-devel find /usr -name "mysql.h" 2>/dev/null find /usr/local -name "mysql.h" 2>/dev/null find /opt -name "mysql.h" 2>/dev/null
报错 找不到 -lmysqlclient
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 sudo yum install mysql-devel mysql-community-develfind /usr -name "libmysqlclient.so*" 2>/dev/null sudo ln -s /usr/lib64/mysql/libmysqlclient.so.18 /usr/lib64/libmysqlclient.sosudo ldconfigldconfig -p | grep mysql
2.运行客户端
使用 curl
1 2 curl http://localhost:1316/
使用浏览器
打开浏览器
访问 http://localhost:1316/
项目介绍 小白视角:一文读懂社长的TinyWebServer | HU
线程同步机制封装类 最新版Web服务器项目详解 - 01 线程同步机制封装类
不需要,使用 lock_guard 和 unique_lock 即可
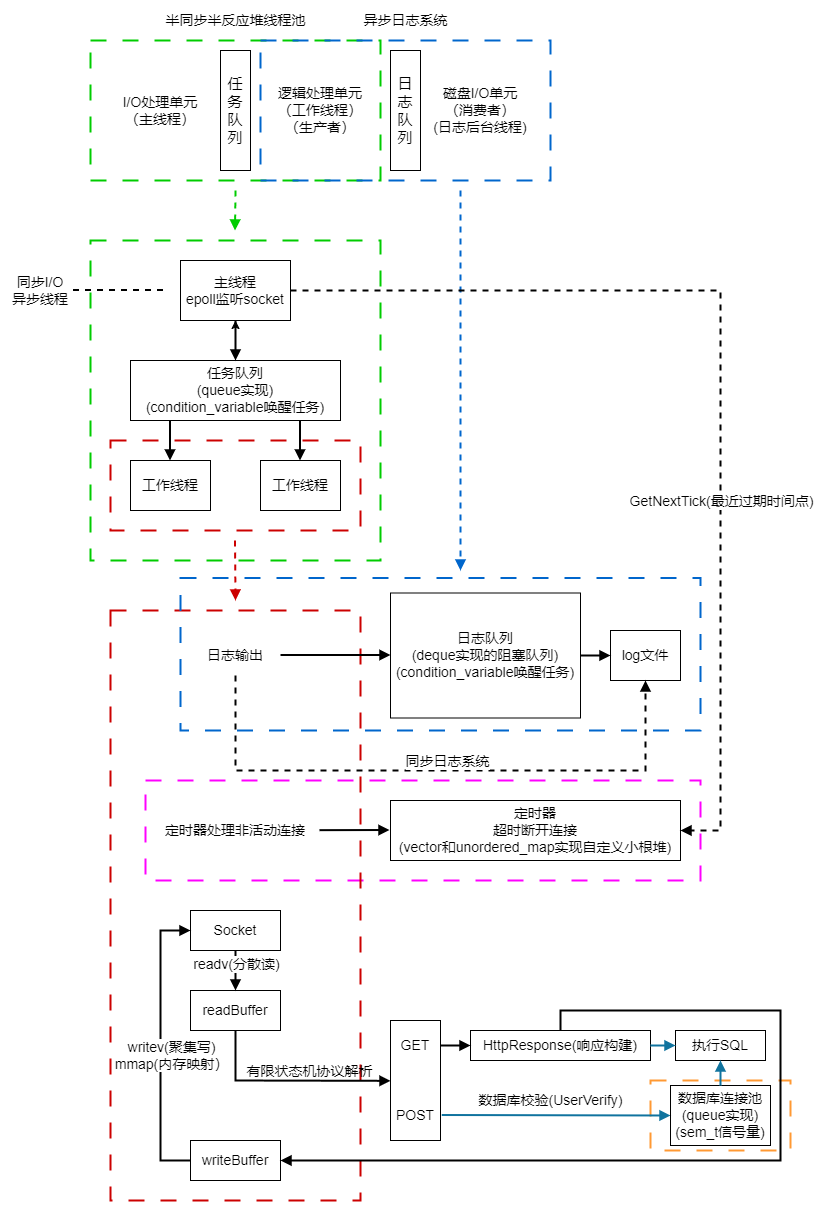
半同步半反应堆线程池 最新版Web服务器项目详解 - 02 半同步半反应堆线程池(上)
最新版Web服务器项目详解 - 03 半同步半反应堆线程池(下)
ThreadPool类:线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #ifndef THREADPOOL_H #define THREADPOOL_H #include <mutex> #include <condition_variable> #include <queue> #include <thread> #include <functional> class ThreadPool {public : explicit ThreadPool (size_t threadCount = 8 ) : pool_(std::make_shared<Pool>()) { assert (threadCount > 0 ); for (size_t i = 0 ; i < threadCount; i++) { std::thread ([pool = pool_] { std::unique_lock<std::mutex> locker (pool->mtx); while (true ) { if (!pool->tasks.empty ()) { auto task = std::move (pool->tasks.front ()); pool->tasks.pop (); locker.unlock (); task (); locker.lock (); } else if (pool->isClosed) break ; else pool->cond.wait (locker); } }).detach (); } } ThreadPool () = default ; ThreadPool (ThreadPool&&) = default ; ~ThreadPool () { if (static_cast <bool >(pool_)) { { std::lock_guard<std::mutex> locker (pool_->mtx) ; pool_->isClosed = true ; } pool_->cond.notify_all (); } } template <class F> void AddTask (F&& task) { { std::lock_guard<std::mutex> locker (pool_->mtx) ; pool_->tasks.emplace (std::forward<F>(task)); } pool_->cond.notify_one (); } private : struct Pool { std::mutex mtx; std::condition_variable cond; bool isClosed; std::queue<std::function<void ()>> tasks; }; std::shared_ptr<Pool> pool_; }; #endif
http连接处理 最新版Web服务器项目详解 - 04 http连接处理(上)
最新版Web服务器项目详解 - 05 http连接处理(中)
最新版Web服务器项目详解 - 06 http连接处理(下)
Buffer类:自动增长的缓冲区 在高性能网络编程中,非阻塞 I/O 要求我们必须有缓冲区:
读缓冲区 :底层网络数据可能只到达了一部分,我们需要先把收到的数据存起来,直到凑够一个完整的 HTTP 请求报文写缓冲区 :我们要发送的数据可能很大,内核缓冲区满了发送不完,我们需要把剩下的数据暂存,等 Socket 可写时继续发送
Buffer 类 内部维护了一个 std::vector<char>,它将内存逻辑上分成了三部分:
Prependable (预留/已读区) :0 到 readPos_ 之间的空间。Readable (可读区/有效数据区) :readPos_ 到 writePos_ 之间的空间。Writable (可写区) :writePos_ 到 buffer_.size() 之间的空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 #ifndef BUFFER_H #define BUFFER_H #include <cstring> #include <iostream> #include <unistd.h> #include <sys/uio.h> #include <vector> #include <atomic> #include <assert.h> class Buffer {public : Buffer (int initBuffSize = 1024 ); ~Buffer () = default ; size_t WritableBytes () const size_t ReadableBytes () const size_t PrependableBytes () const const char * Peek () const const char * BeginWriteConst () const char * BeginWrite () void EnsureWriteable (size_t len) void HasWritten (size_t len) void Append (const std::string& str) void Append (const char * str, size_t len) void Append (const void * data, size_t len) void Append (const Buffer& buff) void Retrieve (size_t len) void RetrieveUntil (const char * end) void RetrieveAll () std::string RetrieveAllToStr () ; ssize_t ReadFd (int fd, int * Errno) ssize_t WriteFd (int fd, int * Errno) private : char * BeginPtr_ () const char * BeginPtr_ () const void MakeSpace_ (size_t len) std::vector<char > buffer_; std::atomic<std::size_t > readPos_; std::atomic<std::size_t > writePos_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 #include "buffer.h" Buffer::Buffer (int initBuffSize) : buffer_ (initBuffSize), readPos_ (0 ), writePos_ (0 ) {} size_t Buffer::ReadableBytes () const return writePos_ - readPos_; } size_t Buffer::WritableBytes () const return buffer_.size () - writePos_; } size_t Buffer::PrependableBytes () const return readPos_; } const char * Buffer::Peek () const return BeginPtr_ () + readPos_; } const char * Buffer::BeginWriteConst () const return BeginPtr_ () + writePos_; } char * Buffer::BeginWrite () return BeginPtr_ () + writePos_; } void Buffer::EnsureWriteable (size_t len) if (WritableBytes () < len) { MakeSpace_ (len); } assert (WritableBytes () >= len); } void Buffer::HasWritten (size_t len) writePos_ += len; } void Buffer::Append (const std::string& str) Append (str.data (), str.length ()); } void Buffer::Append (const void * data, size_t len) assert (data); Append (static_cast <const char *>(data), len); } void Buffer::Append (const char * str, size_t len) assert (str); EnsureWriteable (len); std::copy (str, str + len, BeginWrite ()); HasWritten (len); } void Buffer::Append (const Buffer& buff) Append (buff.Peek (), buff.ReadableBytes ()); } void Buffer::Retrieve (size_t len) assert (len <= ReadableBytes ()); readPos_ += len; } void Buffer::RetrieveUntil (const char * end) assert (Peek () <= end ); Retrieve (end - Peek ()); } void Buffer::RetrieveAll () bzero (&buffer_[0 ], buffer_.size ()); readPos_ = 0 ; writePos_ = 0 ; } std::string Buffer::RetrieveAllToStr () { std::string str (Peek(), ReadableBytes()) ; RetrieveAll (); return str; } ssize_t Buffer::ReadFd (int fd, int * saveErrno) char buff[65535 ]; struct iovec iov[2 ]; const size_t writable = WritableBytes (); iov[0 ].iov_base = BeginPtr_ () + writePos_; iov[0 ].iov_len = writable; iov[1 ].iov_base = buff; iov[1 ].iov_len = sizeof (buff); const ssize_t len = readv (fd, iov, 2 ); if (len < 0 ) { *saveErrno = errno; } else if (static_cast <size_t >(len) <= writable) { writePos_ += len; } else { writePos_ = buffer_.size (); Append (buff, len - writable); } return len; } ssize_t Buffer::WriteFd (int fd, int * saveErrno) size_t readSize = ReadableBytes (); ssize_t len = write (fd, Peek (), readSize); if (len < 0 ) { *saveErrno = errno; return len; } readPos_ += len; return len; } char * Buffer::BeginPtr_ () return &*buffer_.begin (); } const char * Buffer::BeginPtr_ () const return &*buffer_.begin (); } void Buffer::MakeSpace_ (size_t len) if (WritableBytes () + PrependableBytes () < len) { buffer_.resize (writePos_ + len + 1 ); } else { size_t readable = ReadableBytes (); std::copy (BeginPtr_ () + readPos_, BeginPtr_ () + writePos_, BeginPtr_ ()); readPos_ = 0 ; writePos_ = readPos_ + readable; assert (readable == ReadableBytes ()); } }
HttpConn类:核心抽象 在高性能网络服务器中,每一个新连入的客户端都会被封装成一个 HttpConn 对象。它就像一个“管家”,负责管理该连接的所有生命周期:接收数据、解析请求、生成响应、发送数据
基础网络属性 这部分成员负责维护该连接的底层套接字(Socket)信息
fd_ : 该连接对应的文件描述符(Socket)。所有的读写操作都通过这个 fd_ 进行addr_ : 客户端的地址信息(IP 和 端口)isClose_ : 标记该连接是否已经关闭userCount (static) : 静态原子变量 。记录当前服务器总共有多少个活跃的客户端连接。所有 HttpConn 对象共享这一个计数器isET (static) : 是否启用 Edge Triggered (边缘触发) 模式。这决定了服务器处理 IO 的行为(是读一次还是读到尽头)
缓冲区 (核心组件) 使用 Buffer 类
readBuff_ : 读缓冲区 。从客户端读入的原始字节流会先存放在这里,等待 HttpRequest 去解析。writeBuff_ : 写缓冲区 。存放生成的 HTTP 响应报文头(Header)。注意:这里设计了两个缓冲区,实现了读写分离 ,能高效处理非阻塞 IO。
协议处理模块 (业务逻辑) HttpConn 并不自己去一点点解析 HTTP 字符串,而是交给两个专门的类:
request_ (HttpRequest) : 负责“解析”。它会从 readBuff_ 中读取数据,利用状态机识别出 Method (GET/POST)、URL、Headers 等response_ (HttpResponse) : 负责“生成”。根据 request_ 解析出的结果,去磁盘查找对应的文件(如 index.html),并构建响应报文(状态码 200/404 等)
聚集写技术 (Gather Write) HttpConn::write 性能优化的关键点
iov_ (struct iovec) : 一个数组。它在 writev 系统调用中使用。意义 :当服务器发送响应时,通常有两个部分:
响应头 (在 writeBuff_ 中)。响应体 (即请求的文件,通常通过 mmap 映射到内存)。
如果没有 iovec,你需要把这两个部分拷贝到一个连续的内存里再发送。
有了 iovec,你可以直接告诉内核:“第一部分在 A 地址(响应头),第二部分在 B 地址(文件内容),请一起发出去。” 这样避免了额外的内存拷贝,提高了性能
HttpConn 的工作流
Read : epoll 触发读事件 -> 调用 HttpConn::read -> 数据进 readBuff_Process : 调用 HttpConn::process -> request_ 解析数据 -> response_ 生成响应内容并映射文件 -> 填充 iov_Write : epoll 触发写事件 -> 调用 HttpConn::write -> 通过 writev (利用 iov_) 将头和文件发出去Finish : 根据 IsKeepAlive 决定是 Close 还是重新初始化等待下一次请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #ifndef HTTP_CONN_H #define HTTP_CONN_H #include <sys/types.h> #include <sys/uio.h> #include <arpa/inet.h> #include <stdlib.h> #include <errno.h> #include "../log/log.h" #include "../pool/sqlconnRAII.h" #include "../buffer/buffer.h" #include "httprequest.h" #include "httpresponse.h" class HttpConn {public : HttpConn (); ~HttpConn (); void init (int sockFd, const sockaddr_in& addr) ssize_t read (int * saveErrno) ssize_t write (int * saveErrno) void Close () int GetFd () const int GetPort () const const char * GetIP () const sockaddr_in GetAddr () const ; bool process () int ToWriteBytes () return iov_[0 ].iov_len + iov_[1 ].iov_len; } bool IsKeepAlive () const return request_.IsKeepAlive (); } static bool isET; static const char * srcDir; static std::atomic<int > userCount; private : int fd_; struct sockaddr_in addr_; bool isClose_; int iovCnt_; struct iovec iov_[2 ]; Buffer readBuff_; Buffer writeBuff_; HttpRequest request_; HttpResponse response_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 #include "httpconn.h" using namespace std;const char * HttpConn::srcDir;std::atomic<int > HttpConn::userCount; bool HttpConn::isET;HttpConn::HttpConn () { fd_ = -1 ; addr_ = { 0 }; isClose_ = true ; }; HttpConn::~HttpConn () { Close (); }; void HttpConn::init (int fd, const sockaddr_in& addr) assert (fd > 0 ); userCount++; addr_ = addr; fd_ = fd; writeBuff_.RetrieveAll (); readBuff_.RetrieveAll (); isClose_ = false ; LOG_INFO ("Client[%d](%s:%d) in, userCount:%d" , fd_, GetIP (), GetPort (), (int )userCount); } void HttpConn::Close () response_.UnmapFile (); if (isClose_ == false ){ isClose_ = true ; userCount--; close (fd_); LOG_INFO ("Client[%d](%s:%d) quit, UserCount:%d" , fd_, GetIP (), GetPort (), (int )userCount); } } int HttpConn::GetFd () const return fd_; }; struct sockaddr_in HttpConn::GetAddr () const { return addr_; } const char * HttpConn::GetIP () const return inet_ntoa (addr_.sin_addr); } int HttpConn::GetPort () const return addr_.sin_port; } ssize_t HttpConn::read (int * saveErrno) ssize_t len = -1 ; do { len = readBuff_.ReadFd (fd_, saveErrno); if (len <= 0 ) { break ; } } while (isET); return len; } ssize_t HttpConn::write (int * saveErrno) ssize_t len = -1 ; do { len = writev (fd_, iov_, iovCnt_); if (len <= 0 ) { *saveErrno = errno; break ; } if (iov_[0 ].iov_len + iov_[1 ].iov_len == 0 ) { break ; } else if (static_cast <size_t >(len) > iov_[0 ].iov_len) { iov_[1 ].iov_base = (uint8_t *) iov_[1 ].iov_base + (len - iov_[0 ].iov_len); iov_[1 ].iov_len -= (len - iov_[0 ].iov_len); if (iov_[0 ].iov_len) { writeBuff_.RetrieveAll (); iov_[0 ].iov_len = 0 ; } } else { iov_[0 ].iov_base = (uint8_t *)iov_[0 ].iov_base + len; iov_[0 ].iov_len -= len; writeBuff_.Retrieve (len); } } while (isET || ToWriteBytes () > 10240 ); return len; } bool HttpConn::process () request_.Init (); if (readBuff_.ReadableBytes () <= 0 ) { return false ; } else if (request_.parse (readBuff_)) { LOG_DEBUG ("%s" , request_.path ().c_str ()); response_.Init (srcDir, request_.path (), request_.IsKeepAlive (), 200 ); } else { response_.Init (srcDir, request_.path (), false , 400 ); } response_.MakeResponse (writeBuff_); iov_[0 ].iov_base = const_cast <char *>(writeBuff_.Peek ()); iov_[0 ].iov_len = writeBuff_.ReadableBytes (); iovCnt_ = 1 ; if (response_.FileLen () > 0 && response_.File ()) { iov_[1 ].iov_base = response_.File (); iov_[1 ].iov_len = response_.FileLen (); iovCnt_ = 2 ; } LOG_DEBUG ("filesize:%d, %d to %d" , response_.FileLen () , iovCnt_, ToWriteBytes ()); return true ; }
Epoller类:IO 多路复用 Epoller 类是该项目的IO 多路复用模块。它对 Linux 系统调用 epoll 进行了封装,是整个 Reactor 模式 的核心驱动引擎。它的存在意义是将底层的、繁琐的 C 语言风格系统调用,转化成易于使用的 C++ 面向对象接口,并利用 RAII 机制管理资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #ifndef EPOLLER_H #define EPOLLER_H #include <sys/epoll.h> #include <fcntl.h> #include <unistd.h> #include <assert.h> #include <vector> #include <errno.h> class Epoller {public : explicit Epoller (int maxEvent = 1024 ) ~Epoller (); bool AddFd (int fd, uint32_t events) bool ModFd (int fd, uint32_t events) bool DelFd (int fd) int Wait (int timeoutMs = -1 ) int GetEventFd (size_t i) const uint32_t GetEvents (size_t i) const private : int epollFd_; std::vector<struct epoll_event> events_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include "epoller.h" Epoller::Epoller (int maxEvent):epollFd_ (epoll_create (512 )), events_ (maxEvent){ assert (epollFd_ >= 0 && events_.size () > 0 ); } Epoller::~Epoller () { close (epollFd_); } bool Epoller::AddFd (int fd, uint32_t events) if (fd < 0 ) return false ; epoll_event ev = {0 }; ev.data.fd = fd; ev.events = events; return 0 == epoll_ctl (epollFd_, EPOLL_CTL_ADD, fd, &ev); } bool Epoller::ModFd (int fd, uint32_t events) if (fd < 0 ) return false ; epoll_event ev = {0 }; ev.data.fd = fd; ev.events = events; return 0 == epoll_ctl (epollFd_, EPOLL_CTL_MOD, fd, &ev); } bool Epoller::DelFd (int fd) if (fd < 0 ) return false ; epoll_event ev = {0 }; return 0 == epoll_ctl (epollFd_, EPOLL_CTL_DEL, fd, &ev); } int Epoller::Wait (int timeoutMs) return epoll_wait (epollFd_, &events_[0 ], static_cast <int >(events_.size ()), timeoutMs); } int Epoller::GetEventFd (size_t i) const assert (i < events_.size () && i >= 0 ); return events_[i].data.fd; } uint32_t Epoller::GetEvents (size_t i) const assert (i < events_.size () && i >= 0 ); return events_[i].events; }
WebServer类:整个项目的**“大脑”或 “总指挥部”** WebServer 类是整个项目的**“大脑”或 “总指挥部”**。它将所有独立模块(Epoller、ThreadPool、Timer、HttpConn、SqlConnPool)整合在一起,实现了一个完整的、事件驱动的高性能 Web 服务器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #ifndef WEBSERVER_H #define WEBSERVER_H #include <unordered_map> #include <fcntl.h> #include <unistd.h> #include <assert.h> #include <errno.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include "epoller.h" #include "../log/log.h" #include "../timer/heaptimer.h" #include "../pool/sqlconnpool.h" #include "../pool/threadpool.h" #include "../pool/sqlconnRAII.h" #include "../http/httpconn.h" class WebServer {public : WebServer ( int port, int trigMode, int timeoutMS, bool OptLinger, int sqlPort, const char * sqlUser, const char * sqlPwd, const char * dbName, int connPoolNum, int threadNum, bool openLog, int logLevel, int logQueSize); ~WebServer (); void Start () private : bool InitSocket_ () void InitEventMode_ (int trigMode) void AddClient_ (int fd, sockaddr_in addr) void DealListen_ () void DealWrite_ (HttpConn* client) void DealRead_ (HttpConn* client) void SendError_ (int fd, const char *info) void ExtentTime_ (HttpConn* client) void CloseConn_ (HttpConn* client) void OnRead_ (HttpConn* client) void OnWrite_ (HttpConn* client) void OnProcess (HttpConn* client) static const int MAX_FD = 65536 ; static int SetFdNonblock (int fd) bool openLinger_; int timeoutMS_; bool isClose_; int port_; int listenFd_; char * srcDir_; uint32_t listenEvent_; uint32_t connEvent_; std::unique_ptr<HeapTimer> timer_; std::unique_ptr<ThreadPool> threadpool_; std::unique_ptr<Epoller> epoller_; std::unordered_map<int , HttpConn> users_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 #include "webserver.h" using namespace std;WebServer::WebServer ( int port, int trigMode, int timeoutMS, bool OptLinger, int sqlPort, const char * sqlUser, const char * sqlPwd, const char * dbName, int connPoolNum, int threadNum, bool openLog, int logLevel, int logQueSize): port_ (port), openLinger_ (OptLinger), timeoutMS_ (timeoutMS), isClose_ (false ), timer_ (new HeapTimer ()), threadpool_ (new ThreadPool (threadNum)), epoller_ (new Epoller ()) { srcDir_ = getcwd (nullptr , 256 ); assert (srcDir_); strncat (srcDir_, "/resources/" , 16 ); HttpConn::userCount = 0 ; HttpConn::srcDir = srcDir_; SqlConnPool::Instance ()->Init ("localhost" , sqlPort, sqlUser, sqlPwd, dbName, connPoolNum); InitEventMode_ (trigMode); if (!InitSocket_ ()) { isClose_ = true ;} if (openLog) { Log::Instance ()->init (logLevel, "./log" , ".log" , logQueSize); if (isClose_) { LOG_ERROR ("========== Server init error!==========" ); } else { LOG_INFO ("========== Server init ==========" ); LOG_INFO ("Port:%d, OpenLinger: %s" , port_, OptLinger? "true" :"false" ); LOG_INFO ("Listen Mode: %s, OpenConn Mode: %s" , (listenEvent_ & EPOLLET ? "ET" : "LT" ), (connEvent_ & EPOLLET ? "ET" : "LT" )); LOG_INFO ("LogSys level: %d" , logLevel); LOG_INFO ("srcDir: %s" , HttpConn::srcDir); LOG_INFO ("SqlConnPool num: %d, ThreadPool num: %d" , connPoolNum, threadNum); } } } WebServer::~WebServer () { close (listenFd_); isClose_ = true ; free (srcDir_); SqlConnPool::Instance ()->ClosePool (); } void WebServer::InitEventMode_ (int trigMode) listenEvent_ = EPOLLRDHUP; connEvent_ = EPOLLONESHOT | EPOLLRDHUP; switch (trigMode) { case 0 : break ; case 1 : connEvent_ |= EPOLLET; break ; case 2 : listenEvent_ |= EPOLLET; break ; case 3 : listenEvent_ |= EPOLLET; connEvent_ |= EPOLLET; break ; default : listenEvent_ |= EPOLLET; connEvent_ |= EPOLLET; break ; } HttpConn::isET = (connEvent_ & EPOLLET); } void WebServer::Start () int timeMS = -1 ; if (!isClose_) { LOG_INFO ("========== Server start ==========" ); } while (!isClose_) { if (timeoutMS_ > 0 ) { timeMS = timer_->GetNextTick (); } int eventCnt = epoller_->Wait (timeMS); for (int i = 0 ; i < eventCnt; i++) { int fd = epoller_->GetEventFd (i); uint32_t events = epoller_->GetEvents (i); if (fd == listenFd_) { DealListen_ (); } else if (events & (EPOLLRDHUP | EPOLLHUP | EPOLLERR)) { assert (users_.count (fd) > 0 ); CloseConn_ (&users_[fd]); } else if (events & EPOLLIN) { assert (users_.count (fd) > 0 ); DealRead_ (&users_[fd]); } else if (events & EPOLLOUT) { assert (users_.count (fd) > 0 ); DealWrite_ (&users_[fd]); } else { LOG_ERROR ("Unexpected event" ); } } } } void WebServer::SendError_ (int fd, const char *info) assert (fd > 0 ); int ret = send (fd, info, strlen (info), 0 ); if (ret < 0 ) { LOG_WARN ("send error to client[%d] error!" , fd); } close (fd); } void WebServer::CloseConn_ (HttpConn* client) assert (client); LOG_INFO ("Client[%d] quit!" , client->GetFd ()); epoller_->DelFd (client->GetFd ()); client->Close (); } void WebServer::AddClient_ (int fd, sockaddr_in addr) assert (fd > 0 ); users_[fd].init (fd, addr); if (timeoutMS_ > 0 ) { timer_->add (fd, timeoutMS_, std::bind (&WebServer::CloseConn_, this , &users_[fd])); } epoller_->AddFd (fd, EPOLLIN | connEvent_); SetFdNonblock (fd); LOG_INFO ("Client[%d] in!" , users_[fd].GetFd ()); } void WebServer::DealListen_ () struct sockaddr_in addr; socklen_t len = sizeof (addr); do { int fd = accept (listenFd_, (struct sockaddr *)&addr, &len); if (fd <= 0 ) { return ;} else if (HttpConn::userCount >= MAX_FD) { SendError_ (fd, "Server busy!" ); LOG_WARN ("Clients is full!" ); return ; } AddClient_ (fd, addr); } while (listenEvent_ & EPOLLET); } void WebServer::DealRead_ (HttpConn* client) assert (client); ExtentTime_ (client); threadpool_->AddTask (std::bind (&WebServer::OnRead_, this , client)); } void WebServer::DealWrite_ (HttpConn* client) assert (client); ExtentTime_ (client); threadpool_->AddTask (std::bind (&WebServer::OnWrite_, this , client)); } void WebServer::ExtentTime_ (HttpConn* client) assert (client); if (timeoutMS_ > 0 ) { timer_->adjust (client->GetFd (), timeoutMS_); } } void WebServer::OnRead_ (HttpConn* client) assert (client); int ret = -1 ; int readErrno = 0 ; ret = client->read (&readErrno); if (ret <= 0 && readErrno != EAGAIN) { CloseConn_ (client); return ; } OnProcess (client); } void WebServer::OnProcess (HttpConn* client) if (client->process ()) { epoller_->ModFd (client->GetFd (), connEvent_ | EPOLLOUT); } else { epoller_->ModFd (client->GetFd (), connEvent_ | EPOLLIN); } } void WebServer::OnWrite_ (HttpConn* client) assert (client); int ret = -1 ; int writeErrno = 0 ; ret = client->write (&writeErrno); if (client->ToWriteBytes () == 0 ) { if (client->IsKeepAlive ()) { OnProcess (client); return ; } } else if (ret < 0 ) { if (writeErrno == EAGAIN) { epoller_->ModFd (client->GetFd (), connEvent_ | EPOLLOUT); return ; } } CloseConn_ (client); } bool WebServer::InitSocket_ () int ret; struct sockaddr_in addr; if (port_ > 65535 || port_ < 1024 ) { LOG_ERROR ("Port:%d error!" , port_); return false ; } addr.sin_family = AF_INET; addr.sin_addr.s_addr = htonl (INADDR_ANY); addr.sin_port = htons (port_); struct linger optLinger = { 0 }; if (openLinger_) { optLinger.l_onoff = 1 ; optLinger.l_linger = 1 ; } listenFd_ = socket (AF_INET, SOCK_STREAM, 0 ); if (listenFd_ < 0 ) { LOG_ERROR ("Create socket error!" , port_); return false ; } ret = setsockopt (listenFd_, SOL_SOCKET, SO_LINGER, &optLinger, sizeof (optLinger)); if (ret < 0 ) { close (listenFd_); LOG_ERROR ("Init linger error!" , port_); return false ; } int optval = 1 ; ret = setsockopt (listenFd_, SOL_SOCKET, SO_REUSEADDR, (const void *)&optval, sizeof (int )); if (ret == -1 ) { LOG_ERROR ("set socket setsockopt error !" ); close (listenFd_); return false ; } ret = bind (listenFd_, (struct sockaddr *)&addr, sizeof (addr)); if (ret < 0 ) { LOG_ERROR ("Bind Port:%d error!" , port_); close (listenFd_); return false ; } ret = listen (listenFd_, 6 ); if (ret < 0 ) { LOG_ERROR ("Listen port:%d error!" , port_); close (listenFd_); return false ; } ret = epoller_->AddFd (listenFd_, listenEvent_ | EPOLLIN); if (ret == 0 ) { LOG_ERROR ("Add listen error!" ); close (listenFd_); return false ; } SetFdNonblock (listenFd_); LOG_INFO ("Server port:%d" , port_); return true ; } int WebServer::SetFdNonblock (int fd) assert (fd > 0 ); return fcntl (fd, F_SETFL, fcntl (fd, F_GETFD, 0 ) | O_NONBLOCK); }
HttpRequest类:协议解析器 HttpRequest 类是 WebServer 中的“协议解析器 ”。它的核心任务是将 Buffer 中的原始字节流,按照 HTTP 协议的规范,解析成结构化的信息(如请求方法、URL、Header、Body 等),供后续业务逻辑使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 #ifndef HTTP_REQUEST_H #define HTTP_REQUEST_H #include <unordered_map> #include <unordered_set> #include <string> #include <regex> #include <errno.h> #include <mysql/mysql.h> #include "../buffer/buffer.h" #include "../log/log.h" #include "../pool/sqlconnpool.h" #include "../pool/sqlconnRAII.h" class HttpRequest {public : enum PARSE_STATE { REQUEST_LINE, HEADERS, BODY, FINISH, }; enum HTTP_CODE { NO_REQUEST = 0 , GET_REQUEST, BAD_REQUEST, NO_RESOURSE, FORBIDDENT_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION, }; HttpRequest () { Init (); } ~HttpRequest () = default ; void Init () bool parse (Buffer& buff) std::string path () const ; std::string& path () ; std::string method () const ; std::string version () const ; std::string GetPost (const std::string& key) const ; std::string GetPost (const char * key) const ; bool IsKeepAlive () const private : bool ParseRequestLine_ (const std::string& line) void ParseHeader_ (const std::string& line) void ParseBody_ (const std::string& line) void ParsePath_ () void ParsePost_ () void ParseFromUrlencoded_ () static bool UserVerify (const std::string& name, const std::string& pwd, bool isLogin) PARSE_STATE state_; std::string method_, path_, version_, body_; std::unordered_map<std::string, std::string> header_; std::unordered_map<std::string, std::string> post_; static const std::unordered_set<std::string> DEFAULT_HTML; static const std::unordered_map<std::string, int > DEFAULT_HTML_TAG; static int ConverHex (char ch) }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 #include "httprequest.h" using namespace std;const unordered_set<string> HttpRequest::DEFAULT_HTML{ "/index" , "/register" , "/login" , "/welcome" , "/video" , "/picture" , }; const unordered_map<string, int > HttpRequest::DEFAULT_HTML_TAG { {"/register.html" , 0 }, {"/login.html" , 1 }, }; void HttpRequest::Init () method_ = path_ = version_ = body_ = "" ; state_ = REQUEST_LINE; header_.clear (); post_.clear (); } bool HttpRequest::IsKeepAlive () const if (header_.count ("Connection" ) == 1 ) { return header_.find ("Connection" )->second == "keep-alive" && version_ == "1.1" ; } return false ; } bool HttpRequest::parse (Buffer& buff) const char CRLF[] = "\r\n" ; if (buff.ReadableBytes () <= 0 ) { return false ; } while (buff.ReadableBytes () && state_ != FINISH) { const char * lineEnd = search (buff.Peek (), buff.BeginWriteConst (), CRLF, CRLF + 2 ); std::string line (buff.Peek(), lineEnd) ; switch (state_) { case REQUEST_LINE: if (!ParseRequestLine_ (line)) { return false ; } ParsePath_ (); break ; case HEADERS: ParseHeader_ (line); if (buff.ReadableBytes () <= 2 ) { state_ = FINISH; } break ; case BODY: ParseBody_ (line); break ; default : break ; } if (lineEnd == buff.BeginWrite ()) { break ; } buff.RetrieveUntil (lineEnd + 2 ); } LOG_DEBUG ("[%s], [%s], [%s]" , method_.c_str (), path_.c_str (), version_.c_str ()); return true ; } void HttpRequest::ParsePath_ () if (path_ == "/" ) { path_ = "/index.html" ; } else { for (auto &item: DEFAULT_HTML) { if (item == path_) { path_ += ".html" ; break ; } } } } bool HttpRequest::ParseRequestLine_ (const string& line) regex patten ("^([^ ]*) ([^ ]*) HTTP/([^ ]*)$" ) ; smatch subMatch; if (regex_match (line, subMatch, patten)) { method_ = subMatch[1 ]; path_ = subMatch[2 ]; version_ = subMatch[3 ]; state_ = HEADERS; return true ; } LOG_ERROR ("RequestLine Error" ); return false ; } void HttpRequest::ParseHeader_ (const string& line) regex patten ("^([^:]*): ?(.*)$" ) ; smatch subMatch; if (regex_match (line, subMatch, patten)) { header_[subMatch[1 ]] = subMatch[2 ]; } else { state_ = BODY; } } void HttpRequest::ParseBody_ (const string& line) body_ = line; ParsePost_ (); state_ = FINISH; LOG_DEBUG ("Body:%s, len:%d" , line.c_str (), line.size ()); } int HttpRequest::ConverHex (char ch) if (ch >= 'A' && ch <= 'F' ) return ch -'A' + 10 ; if (ch >= 'a' && ch <= 'f' ) return ch -'a' + 10 ; return ch; } void HttpRequest::ParsePost_ () if (method_ == "POST" && header_["Content-Type" ] == "application/x-www-form-urlencoded" ) { ParseFromUrlencoded_ (); if (DEFAULT_HTML_TAG.count (path_)) { int tag = DEFAULT_HTML_TAG.find (path_)->second; LOG_DEBUG ("Tag:%d" , tag); if (tag == 0 || tag == 1 ) { bool isLogin = (tag == 1 ); if (UserVerify (post_["username" ], post_["password" ], isLogin)) { path_ = "/welcome.html" ; } else { path_ = "/error.html" ; } } } } } void HttpRequest::ParseFromUrlencoded_ () if (body_.size () == 0 ) { return ; } string key, value; int num = 0 ; int n = body_.size (); int i = 0 , j = 0 ; for (; i < n; i++) { char ch = body_[i]; switch (ch) { case '=' : key = body_.substr (j, i - j); j = i + 1 ; break ; case '+' : body_[i] = ' ' ; break ; case '%' : num = ConverHex (body_[i + 1 ]) * 16 + ConverHex (body_[i + 2 ]); body_[i + 2 ] = num % 10 + '0' ; body_[i + 1 ] = num / 10 + '0' ; i += 2 ; break ; case '&' : value = body_.substr (j, i - j); j = i + 1 ; post_[key] = value; LOG_DEBUG ("%s = %s" , key.c_str (), value.c_str ()); break ; default : break ; } } assert (j <= i); if (post_.count (key) == 0 && j < i) { value = body_.substr (j, i - j); post_[key] = value; } } bool HttpRequest::UserVerify (const string &name, const string &pwd, bool isLogin) if (name == "" || pwd == "" ) { return false ; } LOG_INFO ("Verify name:%s pwd:%s" , name.c_str (), pwd.c_str ()); MYSQL* sql; SqlConnRAII (&sql, SqlConnPool::Instance ()); assert (sql); bool flag = false ; unsigned int j = 0 ; char order[256 ] = { 0 }; MYSQL_FIELD *fields = nullptr ; MYSQL_RES *res = nullptr ; if (!isLogin) { flag = true ; } snprintf (order, 256 , "SELECT username, password FROM user WHERE username='%s' LIMIT 1" , name.c_str ()); LOG_DEBUG ("%s" , order); if (mysql_query (sql, order)) { mysql_free_result (res); return false ; } res = mysql_store_result (sql); j = mysql_num_fields (res); fields = mysql_fetch_fields (res); while (MYSQL_ROW row = mysql_fetch_row (res)) { LOG_DEBUG ("MYSQL ROW: %s %s" , row[0 ], row[1 ]); string password (row[1 ]) ; if (isLogin) { if (pwd == password) { flag = true ; } else { flag = false ; LOG_DEBUG ("pwd error!" ); } } else { flag = false ; LOG_DEBUG ("user used!" ); } } mysql_free_result (res); if (!isLogin && flag == true ) { LOG_DEBUG ("regirster!" ); bzero (order, 256 ); snprintf (order, 256 ,"INSERT INTO user(username, password) VALUES('%s','%s')" , name.c_str (), pwd.c_str ()); LOG_DEBUG ( "%s" , order); if (mysql_query (sql, order)) { LOG_DEBUG ( "Insert error!" ); flag = false ; } flag = true ; } SqlConnPool::Instance ()->FreeConn (sql); LOG_DEBUG ( "UserVerify success!!" ); return flag; } std::string HttpRequest::path () const { return path_; } std::string& HttpRequest::path () { return path_; } std::string HttpRequest::method () const { return method_; } std::string HttpRequest::version () const { return version_; } std::string HttpRequest::GetPost (const std::string& key) const { assert (key != "" ); if (post_.count (key) == 1 ) { return post_.find (key)->second; } return "" ; } std::string HttpRequest::GetPost (const char * key) const { assert (key != nullptr ); if (post_.count (key) == 1 ) { return post_.find (key)->second; } return "" ; }
正则表达式
定位符(告诉正则在哪里匹配)
^ :匹配字符串的开头 。例如 ^abc 表示必须以 abc 开头$ :匹配字符串的结尾 。例如 xyz$ 表示必须以 xyz 结尾\b :匹配一个单词边界 。例如 \bhi\b 只匹配独立的 “hi”,不匹配 “high”
字符组(告诉正则匹配什么字符)
. :匹配除换行符以外的任意单个字符 。它是一个“万用筛子”[abc] :匹配方括号内的任意一个 字符。例如 [aeiou] 匹配任意一个元音字母[^abc] :匹配除了 方括号内字符以外的任意字符。例如 [^ ] 匹配非空格字符[a-z] :匹配 a 到 z 范围内的任意小写字母\d :匹配一个数字 ,等价于 [0-9]\w :匹配一个字母、数字或下划线 ,等价于 [A-Za-z0-9_]\s :匹配一个空白字符 (空格、制表符、换页符等)
量词(告诉正则字符重复几次)
*****:重复 0 次或多次 (即:有没有都行,有多少个都行)
+ :重复 1 次或多次 (即:至少要有一个)? :重复 0 次或 1 次 (即:可选的,最多一个){n} :精确重复 n 次 {n,} :至少重复 n 次 {n,m} :重复 n 到 m 次
分组与分支(正则的逻辑控制)
( ) :分组/捕获 。将一部分规则括起来看作一个整体。它有两个作用:
应用量词,如 (abc){3} 匹配 “abcabcabc”
捕获内容 :匹配成功后,你可以通过 subMatch[1] 等方式单独取出括号里的内容
| :或 运算。例如 cat|dog 匹配 “cat” 或者 “dog”
转义字符(匹配符号本身)
****:如果你想匹配正则里有特殊含义的符号本身(如 . 或 *),就需要在前面加斜杠
拆解正则模版,匹配 GET /index.html HTTP/1.1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 regex patten ("^([^ ]*) ([^ ]*) HTTP/([^ ]*)$" ) ;smatch subMatch; if (regex_match (line, subMatch, patten)) { method_ = subMatch[1 ]; path_ = subMatch[2 ]; version_ = subMatch[3 ]; state_ = HEADERS; return true ; }
^ :匹配字符串的开始 ([^ ]*) :这是第一个关键部分
( ):圆括号表示“捕获组”,意思是要把这部分内容取出来存好
[^ ]:表示“除了空格以外的任意字符”
*:表示“匹配 0 次或多次”
合起来的意思 :从当前位置开始,把所有不是空格 的字符都抓取出来。在 GET /index.html 中,它抓到的就是 GET
(空格):匹配一个真实的空格
([^ ]*) :第二个捕获组。重复上面的逻辑,抓取第二个单词。在例子中抓到的是 /index.htmlHTTP/ :匹配固定字符串“ HTTP/”(注意前面有个空格)([^ ]*) :第三个捕获组。抓取 HTTP/ 之后的内容,也就是版本号(如 1.1)。$ :匹配字符串的结束 。
HttpResponse类:响应构建器 HttpResponse 类是 WebServer 中的**“响应构建器”。它的职责非常明确:根据 HttpRequest 解析出的结果(状态码、资源路径等),构造出符合 HTTP 协议标准的响应报文(包括状态行、响应头、响应体),并将磁盘上的文件通过 内存映射(mmap)**技术加载到进程地址空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 #ifndef HTTP_RESPONSE_H #define HTTP_RESPONSE_H #include <unordered_map> #include <fcntl.h> #include <unistd.h> #include <sys/stat.h> #include <sys/mman.h> #include "../buffer/buffer.h" #include "../log/log.h" class HttpResponse {public : HttpResponse (); ~HttpResponse (); void Init (const std::string& srcDir, std::string& path, bool isKeepAlive = false , int code = -1 ) void UnmapFile () void MakeResponse (Buffer& buff) char * File () size_t FileLen () const void ErrorContent (Buffer& buff, std::string message) int Code () const return code_; } private : void AddStateLine_ (Buffer &buff) void AddHeader_ (Buffer &buff) void AddContent_ (Buffer &buff) void ErrorHtml_ () std::string GetFileType_ () ; int code_; bool isKeepAlive_; std::string path_; std::string srcDir_; char * mmFile_; struct stat mmFileStat_; static const std::unordered_map<std::string, std::string> SUFFIX_TYPE; static const std::unordered_map<int , std::string> CODE_STATUS; static const std::unordered_map<int , std::string> CODE_PATH; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 #include "httpresponse.h" using namespace std;const unordered_map<string, string> HttpResponse::SUFFIX_TYPE = { { ".html" , "text/html" }, { ".xml" , "text/xml" }, { ".xhtml" , "application/xhtml+xml" }, { ".txt" , "text/plain" }, { ".rtf" , "application/rtf" }, { ".pdf" , "application/pdf" }, { ".word" , "application/nsword" }, { ".png" , "image/png" }, { ".gif" , "image/gif" }, { ".jpg" , "image/jpeg" }, { ".jpeg" , "image/jpeg" }, { ".au" , "audio/basic" }, { ".mpeg" , "video/mpeg" }, { ".mpg" , "video/mpeg" }, { ".avi" , "video/x-msvideo" }, { ".gz" , "application/x-gzip" }, { ".tar" , "application/x-tar" }, { ".css" , "text/css " }, { ".js" , "text/javascript " }, }; const unordered_map<int , string> HttpResponse::CODE_STATUS = { { 200 , "OK" }, { 400 , "Bad Request" }, { 403 , "Forbidden" }, { 404 , "Not Found" }, }; const unordered_map<int , string> HttpResponse::CODE_PATH = { { 400 , "/400.html" }, { 403 , "/403.html" }, { 404 , "/404.html" }, }; HttpResponse::HttpResponse () { code_ = -1 ; path_ = srcDir_ = "" ; isKeepAlive_ = false ; mmFile_ = nullptr ; mmFileStat_ = { 0 }; }; HttpResponse::~HttpResponse () { UnmapFile (); } void HttpResponse::Init (const string& srcDir, string& path, bool isKeepAlive, int code) assert (srcDir != "" ); if (mmFile_) { UnmapFile (); } code_ = code; isKeepAlive_ = isKeepAlive; path_ = path; srcDir_ = srcDir; mmFile_ = nullptr ; mmFileStat_ = { 0 }; } void HttpResponse::UnmapFile () if (mmFile_) { munmap (mmFile_, mmFileStat_.st_size); mmFile_ = nullptr ; } } void HttpResponse::MakeResponse (Buffer& buff) if (stat ((srcDir_ + path_).data (), &mmFileStat_) < 0 || S_ISDIR (mmFileStat_.st_mode)) { code_ = 404 ; } else if (!(mmFileStat_.st_mode & S_IROTH)) { code_ = 403 ; } else if (code_ == -1 ) { code_ = 200 ; } ErrorHtml_ (); AddStateLine_ (buff); AddHeader_ (buff); AddContent_ (buff); } char * HttpResponse::File () return mmFile_; } size_t HttpResponse::FileLen () const return mmFileStat_.st_size; } void HttpResponse::ErrorHtml_ () if (CODE_PATH.count (code_) == 1 ) { path_ = CODE_PATH.find (code_)->second; stat ((srcDir_ + path_).data (), &mmFileStat_); } } void HttpResponse::AddStateLine_ (Buffer& buff) string status; if (CODE_STATUS.count (code_) == 1 ) { status = CODE_STATUS.find (code_)->second; } else { code_ = 400 ; status = CODE_STATUS.find (400 )->second; } buff.Append ("HTTP/1.1 " + to_string (code_) + " " + status + "\r\n" ); } void HttpResponse::AddHeader_ (Buffer& buff) buff.Append ("Connection: " ); if (isKeepAlive_) { buff.Append ("keep-alive\r\n" ); buff.Append ("keep-alive: max=6, timeout=120\r\n" ); } else { buff.Append ("close\r\n" ); } buff.Append ("Content-type: " + GetFileType_ () + "\r\n" ); } void HttpResponse::AddContent_ (Buffer& buff) int srcFd = open ((srcDir_ + path_).data (), O_RDONLY); if (srcFd < 0 ) { ErrorContent (buff, "File NotFound!" ); return ; } LOG_DEBUG ("file path %s" , (srcDir_ + path_).data ()); int * mmRet = (int *)mmap (0 , mmFileStat_.st_size, PROT_READ, MAP_PRIVATE, srcFd, 0 ); if (*mmRet == -1 ) { ErrorContent (buff, "File NotFound!" ); return ; } mmFile_ = (char *)mmRet; close (srcFd); buff.Append ("Content-length: " + to_string (mmFileStat_.st_size) + "\r\n\r\n" ); } string HttpResponse::GetFileType_ () { string::size_type idx = path_.find_last_of ('.' ); if (idx == string::npos) { return "text/plain" ; } string suffix = path_.substr (idx); if (SUFFIX_TYPE.count (suffix) == 1 ) { return SUFFIX_TYPE.find (suffix)->second; } return "text/plain" ; } void HttpResponse::ErrorContent (Buffer& buff, string message) string body; string status; body += "<html><title>Error</title>" ; body += "<body bgcolor=\"ffffff\">" ; if (CODE_STATUS.count (code_) == 1 ) { status = CODE_STATUS.find (code_)->second; } else { status = "Bad Request" ; } body += to_string (code_) + " : " + status + "\n" ; body += "<p>" + message + "</p>" ; body += "<hr><em>TinyWebServer</em></body></html>" ; buff.Append ("Content-length: " + to_string (body.size ()) + "\r\n\r\n" ); buff.Append (body); }
定时器处理非活动连接 最新版Web服务器项目详解 - 07 定时器处理非活动连接(上)
最新版Web服务器项目详解 - 08 定时器处理非活动连接(下)
HeapTimer类:定时器管理器 HeapTimer 类是该项目中的定时器管理器 ,监控非活动连接并及时释放资源
如果服务器不清理那些占着连接但不发数据的客户端(例如由于网络异常断开、恶意挂机),文件描述符(FD)很快就会被耗尽,导致新用户无法接入。HeapTimer 利用**小根堆(Min-Heap)**数据结构,以极高的效率解决了这个问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 #ifndef HEAP_TIMER_H #define HEAP_TIMER_H #include <queue> #include <unordered_map> #include <time.h> #include <algorithm> #include <arpa/inet.h> #include <functional> #include <assert.h> #include <chrono> #include "../log/log.h" typedef std::function<void ()> TimeoutCallBack;typedef std::chrono::high_resolution_clock Clock;typedef std::chrono::milliseconds MS;typedef Clock::time_point TimeStamp;struct TimerNode { int id; TimeStamp expires; TimeoutCallBack cb; bool operator <(const TimerNode& t) { return expires < t.expires; } }; class HeapTimer {public : HeapTimer () { heap_.reserve (64 ); } ~HeapTimer () { clear (); } void adjust (int id, int newExpires) void add (int id, int timeOut, const TimeoutCallBack& cb) void doWork (int id) void clear () void tick () void pop () int GetNextTick () private : void del_ (size_t i) void siftup_ (size_t i) bool siftdown_ (size_t index, size_t n) void SwapNode_ (size_t i, size_t j) std::vector<TimerNode> heap_; std::unordered_map<int , size_t > ref_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 #include "heaptimer.h" void HeapTimer::siftup_ (size_t i) assert (i >= 0 && i < heap_.size ()); size_t j = (i - 1 ) / 2 ; while (j >= 0 ) { if (heap_[j] < heap_[i]) { break ; } SwapNode_ (i, j); i = j; j = (i - 1 ) / 2 ; } } void HeapTimer::SwapNode_ (size_t i, size_t j) assert (i >= 0 && i < heap_.size ()); assert (j >= 0 && j < heap_.size ()); std::swap (heap_[i], heap_[j]); ref_[heap_[i].id] = i; ref_[heap_[j].id] = j; } bool HeapTimer::siftdown_ (size_t index, size_t n) assert (index >= 0 && index < heap_.size ()); assert (n >= 0 && n <= heap_.size ()); size_t i = index; size_t j = i * 2 + 1 ; while (j < n) { if (j + 1 < n && heap_[j + 1 ] < heap_[j]) j++; if (heap_[i] < heap_[j]) break ; SwapNode_ (i, j); i = j; j = i * 2 + 1 ; } return i > index; } void HeapTimer::add (int id, int timeout, const TimeoutCallBack& cb) assert (id >= 0 ); size_t i; if (ref_.count (id) == 0 ) { i = heap_.size (); ref_[id] = i; heap_.push_back ({id, Clock::now () + MS (timeout), cb}); siftup_ (i); } else { i = ref_[id]; heap_[i].expires = Clock::now () + MS (timeout); heap_[i].cb = cb; if (!siftdown_ (i, heap_.size ())) { siftup_ (i); } } } void HeapTimer::doWork (int id) if (heap_.empty () || ref_.count (id) == 0 ) { return ; } size_t i = ref_[id]; TimerNode node = heap_[i]; node.cb (); del_ (i); } void HeapTimer::del_ (size_t index) assert (!heap_.empty () && index >= 0 && index < heap_.size ()); size_t i = index; size_t n = heap_.size () - 1 ; assert (i <= n); if (i < n) { SwapNode_ (i, n); if (!siftdown_ (i, n)) { siftup_ (i); } } ref_.erase (heap_.back ().id); heap_.pop_back (); } void HeapTimer::adjust (int id, int timeout) assert (!heap_.empty () && ref_.count (id) > 0 ); heap_[ref_[id]].expires = Clock::now () + MS (timeout);; siftdown_ (ref_[id], heap_.size ()); } void HeapTimer::tick () if (heap_.empty ()) { return ; } while (!heap_.empty ()) { TimerNode node = heap_.front (); if (std::chrono::duration_cast <MS>(node.expires - Clock::now ()).count () > 0 ) { break ; } node.cb (); pop (); } } void HeapTimer::pop () assert (!heap_.empty ()); del_ (0 ); } void HeapTimer::clear () ref_.clear (); heap_.clear (); } int HeapTimer::GetNextTick () tick (); size_t res = -1 ; if (!heap_.empty ()) { res = std::chrono::duration_cast <MS>(heap_.front ().expires - Clock::now ()).count (); if (res < 0 ) { res = 0 ; } } return res; }
日志系统 最新版Web服务器项目详解 - 09 日志系统(上)
最新版Web服务器项目详解 - 10 日志系统(下)
BlockDeque类:阻塞双端队列 BlockDeque(阻塞双端队列)类是多线程编程中一个非常经典的生产者-消费者模型 的实现。在该项目中,它主要用于异步日志系统 :主线程把要写的日志“生产”出来扔进队列,后台日志线程从队列里“消费”并写入磁盘
由于 C++ 标准库的 std::deque 本身不是线程安全的,BlockDeque 通过封装互斥锁和条件变量,使其能够安全地在多线程环境下工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 #ifndef BLOCKQUEUE_H #define BLOCKQUEUE_H #include <mutex> #include <deque> #include <condition_variable> #include <sys/time.h> template <class T >class BlockDeque {public : explicit BlockDeque (size_t MaxCapacity = 1000 ) ~BlockDeque (); void clear () bool empty () bool full () void Close () size_t size () size_t capacity () T front () ; T back () ; void push_back (const T &item) void push_front (const T &item) bool pop (T &item) bool pop (T &item, int timeout) void flush () private : std::deque<T> deq_; size_t capacity_; std::mutex mtx_; bool isClose_; std::condition_variable condConsumer_; std::condition_variable condProducer_; }; template <class T >BlockDeque<T>::BlockDeque (size_t MaxCapacity) :capacity_ (MaxCapacity) { assert (MaxCapacity > 0 ); isClose_ = false ; } template <class T >BlockDeque<T>::~BlockDeque () { Close (); }; template <class T >void BlockDeque<T>::Close () { { std::lock_guard<std::mutex> locker (mtx_) ; deq_.clear (); isClose_ = true ; } condProducer_.notify_all (); condConsumer_.notify_all (); }; template <class T >void BlockDeque<T>::flush () { condConsumer_.notify_one (); }; template <class T >void BlockDeque<T>::clear () { std::lock_guard<std::mutex> locker (mtx_) ; deq_.clear (); } template <class T >T BlockDeque<T>::front () { std::lock_guard<std::mutex> locker (mtx_) ; return deq_.front (); } template <class T >T BlockDeque<T>::back () { std::lock_guard<std::mutex> locker (mtx_) ; return deq_.back (); } template <class T >size_t BlockDeque<T>::size () { std::lock_guard<std::mutex> locker (mtx_) ; return deq_.size (); } template <class T >size_t BlockDeque<T>::capacity () { std::lock_guard<std::mutex> locker (mtx_) ; return capacity_; } template <class T >void BlockDeque<T>::push_back (const T &item) { std::unique_lock<std::mutex> locker (mtx_) ; while (deq_.size () >= capacity_) { condProducer_.wait (locker); } deq_.push_back (item); condConsumer_.notify_one (); } template <class T >void BlockDeque<T>::push_front (const T &item) { std::unique_lock<std::mutex> locker (mtx_) ; while (deq_.size () >= capacity_) { condProducer_.wait (locker); } deq_.push_front (item); condConsumer_.notify_one (); } template <class T >bool BlockDeque<T>::empty () { std::lock_guard<std::mutex> locker (mtx_) ; return deq_.empty (); } template <class T >bool BlockDeque<T>::full (){ std::lock_guard<std::mutex> locker (mtx_) ; return deq_.size () >= capacity_; } template <class T >bool BlockDeque<T>::pop (T &item) { std::unique_lock<std::mutex> locker (mtx_) ; while (deq_.empty ()){ condConsumer_.wait (locker); if (isClose_){ return false ; } } item = deq_.front (); deq_.pop_front (); condProducer_.notify_one (); return true ; } template <class T >bool BlockDeque<T>::pop (T &item, int timeout) { std::unique_lock<std::mutex> locker (mtx_) ; while (deq_.empty ()){ if (condConsumer_.wait_for (locker, std::chrono::seconds (timeout)) == std::cv_status::timeout){ return false ; } if (isClose_){ return false ; } } item = deq_.front (); deq_.pop_front (); condProducer_.notify_one (); return true ; } #endif
Log类 Log 类是 WebServer 项目中的异步日志系统 。在高性能服务器中,日志系统不仅是调试和监控的“黑匣子”,也是性能瓶颈之一
这个类的设计目标是:高性能、非阻塞、自动化管理
同步日志 :日志直接写入文件。缺点是磁盘 I/O 慢,会阻塞主逻辑线程异步日志 :
deque_ (BlockDeque) :作为中转站writeThread_ :后台线程流程 :主线程调用 write,只是把日志字符串推入 deque_(极快);后台线程 AsyncWrite_ 不断从队列取日志并写入磁盘意义 :实现了业务逻辑与磁盘 I/O 的解耦 ,极大地提升了服务器的响应速度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 #ifndef LOG_H #define LOG_H #include <mutex> #include <string> #include <thread> #include <sys/time.h> #include <string.h> #include <stdarg.h> #include <assert.h> #include <sys/stat.h> #include "blockqueue.h" #include "../buffer/buffer.h" class Log {public : void init (int level, const char * path = "./log" , const char * suffix =".log" , int maxQueueCapacity = 1024 ) static Log* Instance () static void FlushLogThread () void write (int level, const char *format,...) void flush () int GetLevel () void SetLevel (int level) bool IsOpen () return isOpen_; } private : Log (); void AppendLogLevelTitle_ (int level) virtual ~Log (); void AsyncWrite_ () private : static const int LOG_PATH_LEN = 256 ; static const int LOG_NAME_LEN = 256 ; static const int MAX_LINES = 50000 ; FILE* fp_; const char * path_; const char * suffix_; int MAX_LINES_; int lineCount_; int toDay_; bool isOpen_; Buffer buff_; int level_; bool isAsync_; std::unique_ptr<BlockDeque<std::string>> deque_; std::unique_ptr<std::thread> writeThread_; std::mutex mtx_; }; #define LOG_BASE(level, format, ...) \ do {\ Log* log = Log::Instance();\ if (log->IsOpen() && log->GetLevel() <= level) {\ log->write(level, format, ##__VA_ARGS__); \ log->flush();\ }\ } while(0); #define LOG_DEBUG(format, ...) do {LOG_BASE(0, format, ##__VA_ARGS__)} while(0); #define LOG_INFO(format, ...) do {LOG_BASE(1, format, ##__VA_ARGS__)} while(0); #define LOG_WARN(format, ...) do {LOG_BASE(2, format, ##__VA_ARGS__)} while(0); #define LOG_ERROR(format, ...) do {LOG_BASE(3, format, ##__VA_ARGS__)} while(0); #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 #include "log.h" using namespace std;Log::Log () { lineCount_ = 0 ; isAsync_ = false ; writeThread_ = nullptr ; deque_ = nullptr ; toDay_ = 0 ; fp_ = nullptr ; } Log::~Log () { if (writeThread_ && writeThread_->joinable ()) { while (!deque_->empty ()) { deque_->flush (); }; deque_->Close (); writeThread_->join (); } if (fp_) { lock_guard<mutex> locker (mtx_) ; flush (); fclose (fp_); } } int Log::GetLevel () lock_guard<mutex> locker (mtx_) ; return level_; } void Log::SetLevel (int level) lock_guard<mutex> locker (mtx_) ; level_ = level; } void Log::init (int level = 1 , const char * path, const char * suffix, int maxQueueSize) isOpen_ = true ; level_ = level; if (maxQueueSize > 0 ) { isAsync_ = true ; if (!deque_) { unique_ptr<BlockDeque<std::string>> newDeque (new BlockDeque<std::string>); deque_ = move (newDeque); std::unique_ptr<std::thread> NewThread (new thread(FlushLogThread)) ; writeThread_ = move (NewThread); } } else { isAsync_ = false ; } lineCount_ = 0 ; time_t timer = time (nullptr ); struct tm *sysTime = localtime (&timer); struct tm t = *sysTime; path_ = path; suffix_ = suffix; char fileName[LOG_NAME_LEN] = {0 }; snprintf (fileName, LOG_NAME_LEN - 1 , "%s/%04d_%02d_%02d%s" , path_, t.tm_year + 1900 , t.tm_mon + 1 , t.tm_mday, suffix_); toDay_ = t.tm_mday; { lock_guard<mutex> locker (mtx_) ; buff_.RetrieveAll (); if (fp_) { flush (); fclose (fp_); } fp_ = fopen (fileName, "a" ); if (fp_ == nullptr ) { mkdir (path_, 0777 ); fp_ = fopen (fileName, "a" ); } assert (fp_ != nullptr ); } } void Log::write (int level, const char *format, ...) struct timeval now = {0 , 0 }; gettimeofday (&now, nullptr ); time_t tSec = now.tv_sec; struct tm *sysTime = localtime (&tSec); struct tm t = *sysTime; va_list vaList; if (toDay_ != t.tm_mday || (lineCount_ && (lineCount_ % MAX_LINES == 0 ))) { unique_lock<mutex> locker (mtx_) ; locker.unlock (); char newFile[LOG_NAME_LEN]; char tail[36 ] = {0 }; snprintf (tail, 36 , "%04d_%02d_%02d" , t.tm_year + 1900 , t.tm_mon + 1 , t.tm_mday); if (toDay_ != t.tm_mday) { snprintf (newFile, LOG_NAME_LEN - 72 , "%s/%s%s" , path_, tail, suffix_); toDay_ = t.tm_mday; lineCount_ = 0 ; } else { snprintf (newFile, LOG_NAME_LEN - 72 , "%s/%s-%d%s" , path_, tail, (lineCount_ / MAX_LINES), suffix_); } locker.lock (); flush (); fclose (fp_); fp_ = fopen (newFile, "a" ); assert (fp_ != nullptr ); } { unique_lock<mutex> locker (mtx_) ; lineCount_++; int n = snprintf (buff_.BeginWrite (), 128 , "%d-%02d-%02d %02d:%02d:%02d.%06ld " , t.tm_year + 1900 , t.tm_mon + 1 , t.tm_mday, t.tm_hour, t.tm_min, t.tm_sec, now.tv_usec); buff_.HasWritten (n); AppendLogLevelTitle_ (level); va_start (vaList, format); int m = vsnprintf (buff_.BeginWrite (), buff_.WritableBytes (), format, vaList); va_end (vaList); buff_.HasWritten (m); buff_.Append ("\n\0" , 2 ); if (isAsync_ && deque_ && !deque_->full ()) { deque_->push_back (buff_.RetrieveAllToStr ()); } else { fputs (buff_.Peek (), fp_); } buff_.RetrieveAll (); } } void Log::AppendLogLevelTitle_ (int level) switch (level) { case 0 : buff_.Append ("[debug]: " , 9 ); break ; case 1 : buff_.Append ("[info] : " , 9 ); break ; case 2 : buff_.Append ("[warn] : " , 9 ); break ; case 3 : buff_.Append ("[error]: " , 9 ); break ; default : buff_.Append ("[info] : " , 9 ); break ; } } void Log::flush () if (isAsync_) { deque_->flush (); } fflush (fp_); } void Log::AsyncWrite_ () string str = "" ; while (deque_->pop (str)) { lock_guard<mutex> locker (mtx_) ; fputs (str.c_str (), fp_); } } Log* Log::Instance () { static Log inst; return &inst; } void Log::FlushLogThread () Log::Instance ()->AsyncWrite_ (); }
数据库连接池 最新版Web服务器项目详解 - 11 数据库连接池
SqlConnPool类 SqlConnPool 类是项目的数据库连接池 模块。在后端开发中,数据库连接是非常昂贵的资源(涉及 TCP 三次握手(后端 <-> 数据库)、身份验证、权限校验等),频繁地创建和销毁连接会严重拖慢服务器响应
该类通过预先创建 并循环利用 一组连接,解决了数据库访问的性能瓶颈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #ifndef SQLCONNPOOL_H #define SQLCONNPOOL_H #include <mysql/mysql.h> #include <string> #include <queue> #include <mutex> #include <semaphore.h> #include <thread> #include "../log/log.h" class SqlConnPool {public : static SqlConnPool *Instance () MYSQL *GetConn () ; void FreeConn (MYSQL * conn) int GetFreeConnCount () void Init (const char * host, int port, const char * user,const char * pwd, const char * dbName, int connSize) void ClosePool () private : SqlConnPool (); ~SqlConnPool (); int MAX_CONN_; int useCount_; int freeCount_; std::queue<MYSQL *> connQue_; std::mutex mtx_; sem_t semId_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #include "sqlconnpool.h" using namespace std;SqlConnPool::SqlConnPool () { useCount_ = 0 ; freeCount_ = 0 ; } SqlConnPool* SqlConnPool::Instance () { static SqlConnPool connPool; return &connPool; } void SqlConnPool::Init (const char * host, int port, const char * user,const char * pwd, const char * dbName, int connSize = 10 ) assert (connSize > 0 ); for (int i = 0 ; i < connSize; i++) { MYSQL *sql = nullptr ; sql = mysql_init (sql); if (!sql) { LOG_ERROR ("MySql init error!" ); assert (sql); } sql = mysql_real_connect (sql, host, user, pwd, dbName, port, nullptr , 0 ); if (!sql) { LOG_ERROR ("MySql Connect error!" ); } connQue_.push (sql); } MAX_CONN_ = connSize; sem_init (&semId_, 0 , MAX_CONN_); } MYSQL* SqlConnPool::GetConn () { MYSQL *sql = nullptr ; if (connQue_.empty ()){ LOG_WARN ("SqlConnPool busy!" ); return nullptr ; } sem_wait (&semId_); { lock_guard<mutex> locker (mtx_) ; sql = connQue_.front (); connQue_.pop (); useCount_++; freeCount_--; } return sql; } void SqlConnPool::FreeConn (MYSQL* sql) assert (sql); lock_guard<mutex> locker (mtx_) ; connQue_.push (sql); sem_post (&semId_); useCount_--; freeCount_++; } void SqlConnPool::ClosePool () lock_guard<mutex> locker (mtx_) ; while (!connQue_.empty ()) { auto item = connQue_.front (); connQue_.pop (); mysql_close (item); } mysql_library_end (); MAX_CONN_ = 0 ; useCount_ = 0 ; freeCount_ = 0 ; } int SqlConnPool::GetFreeConnCount () lock_guard<mutex> locker (mtx_) ; return connQue_.size (); } SqlConnPool::~SqlConnPool () { ClosePool (); }
SqlConnRAII类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #ifndef SQLCONNRAII_H #define SQLCONNRAII_H #include "sqlconnpool.h" class SqlConnRAII {public : SqlConnRAII (MYSQL** sql, SqlConnPool *connpool) { assert (connpool); *sql = connpool->GetConn (); sql_ = *sql; connpool_ = connpool; } ~SqlConnRAII () { if (sql_) { connpool_->FreeConn (sql_); } } private : MYSQL *sql_; SqlConnPool* connpool_; }; #endif
注册登录 最新版Web服务器项目详解 - 12 注册登录
HttpRequest类中
main.cpp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <unistd.h> #include "server/webserver.h" int main () WebServer server ( 1316 , 3 , 60000 , false , 3306 , "root" , "centos" , "tinyWebServer" , 12 , 6 , true , 1 , 1024 ) server.Start (); }
单元测试 测试日志和线程池
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include "../code/log/log.h" #include "../code/pool/threadpool.h" #include <features.h> #if __GLIBC__ == 2 && __GLIBC_MINOR__ < 30 #include <sys/syscall.h> #define gettid() syscall(SYS_gettid) #endif void TestLog () int cnt = 0 , level = 0 ; Log::Instance ()->init (level, "./testlog1" , ".log" , 0 ); for (level = 3 ; level >= 0 ; level--) { Log::Instance ()->SetLevel (level); for (int j = 0 ; j < 10000 ; j++ ){ for (int i = 0 ; i < 4 ; i++) { LOG_BASE (i,"%s 111111111 %d ============= " , "Test" , cnt++); } } } cnt = 0 ; Log::Instance ()->init (level, "./testlog2" , ".log" , 5000 ); for (level = 0 ; level < 4 ; level++) { Log::Instance ()->SetLevel (level); for (int j = 0 ; j < 10000 ; j++ ){ for (int i = 0 ; i < 4 ; i++) { LOG_BASE (i,"%s 222222222 %d ============= " , "Test" , cnt++); } } } } void ThreadLogTask (int i, int cnt) for (int j = 0 ; j < 10000 ; j++ ){ LOG_BASE (i,"PID:[%04d]======= %05d ========= " , gettid (), cnt++); } } void TestThreadPool () Log::Instance ()->init (0 , "./testThreadpool" , ".log" , 5000 ); ThreadPool threadpool (6 ) ; for (int i = 0 ; i < 18 ; i++) { threadpool.AddTask (std::bind (ThreadLogTask, i % 4 , i * 10000 )); } getchar (); } int main () TestLog (); TestThreadPool (); }
压力测试 查看TIME_WAIT连接数
1 netstat -ant |grep “TIME_WAIT” |wc -l
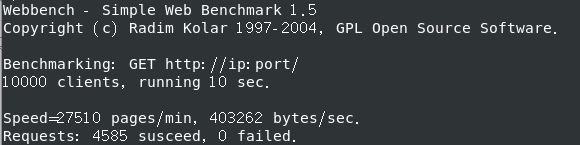
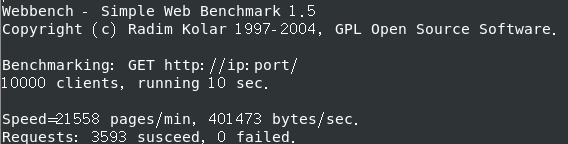
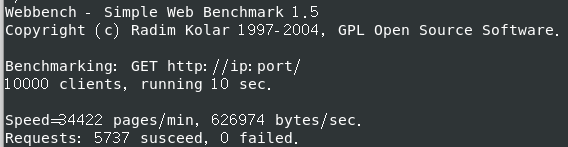
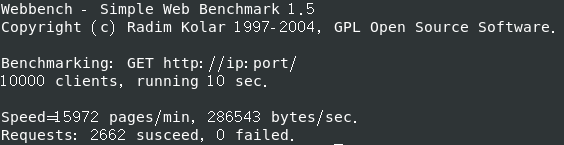
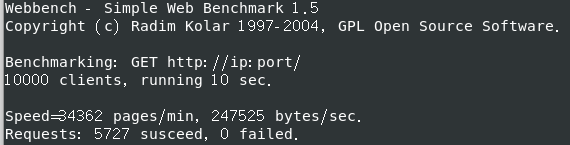
Webbench 测试环境 Linux CentOS 7 64位 cpu: i5-10300H
最开始内存:1G 处理器:1个,处理器内核:2个
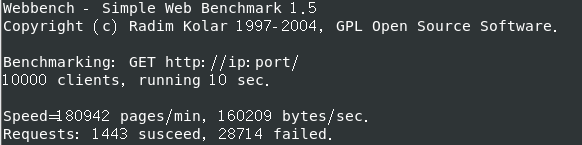
改为内存:2G 处理器:2个,处理器内核:2个
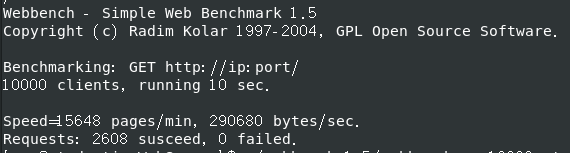
改为内存:2G 处理器:1个,处理器内核:4个
改为内存:2G 处理器:2个,处理器内核:4个
改为内存:8G 处理器:2个,处理器内核:4个,感觉差别不是很大,这个测了五六次有个高的,其他的都只测一次,但是还是远小于项目介绍里面的
QPS (全称是 Queries Per Second ,“每秒查询率” ) 3000+
关日志后 QPS (全称是 Queries Per Second ,“每秒查询率” ) 250+
原理 父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出
测试 -c表示客户端数, -t表示时间
1 ./webbench-1.5/webbench -c 10000 -t 10 http://localhost:1316/
直接解压的webbench-1.5文件夹下的webbench文件可能会因为权限问题找不到命令或者无法执行,这时重新编译一下该文件即可
1 gcc webbench.c -o webbench
报错 1 2 3 4 5 6 problems forking worker no. 3457 fork failed.: Resource temporarily unavailable bash: fork: retry: 没有子进程 bash: fork: retry: 没有子进程 bash: fork: retry: 没有子进程 bash: fork: retry: 没有子进程
报错 Resource temporarily unavailable (错误码 EAGAIN) 意味着 Linux 系统拒绝了创建新进程的请求,因为已经达到了系统允许的最大进程数限制
解决 查看当前限制
临时修改(仅对当前终端有效)
若是使用后,再查看限制发现没变,则触碰到了 Linux 系统中的 “硬限制 (Hard Limit)” ,切换到 root 用户重试
永久修改
1 2 * soft nproc 65535 * hard nproc 65535
再次测试 1 2 ulimit -u 10240./webbench-1.5/webbench -c 10000 -t 10 http://ip:port/
若还是报错,在 CentOS 等系统中,除了 ulimit,还有一个配置文件 会覆盖设置这个 4096 会强制限制普通用户,即便执行了 ulimit 也没用 重新开启一个新的终端窗口
Wrk wg/wrk: Modern HTTP benchmarking tool
下载 1 2 git clone https://github.com/wg/wrk.git cd wrk && make
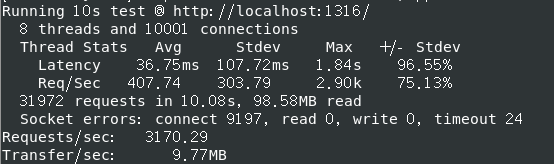
测试环境 Linux CentOS 7 64位 cpu: i5-10300H 内存: 8G 处理器:2个,处理器内核:4个
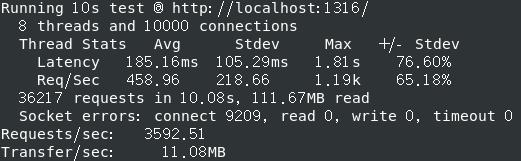
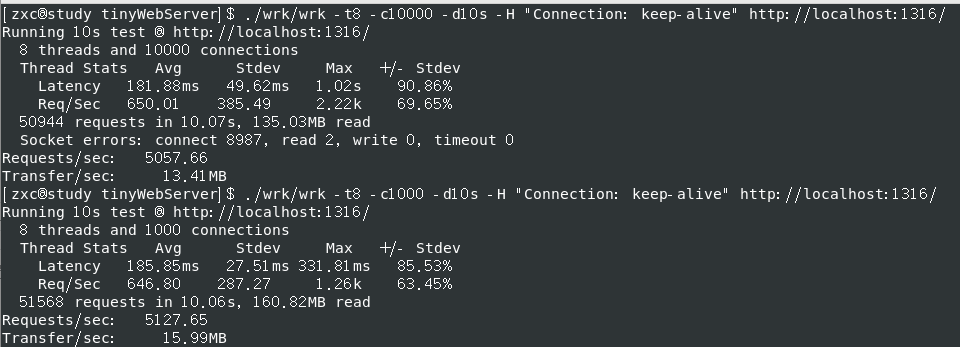
QPS (全称是 Queries Per Second ,“每秒查询率” ) 3000+
关日志后 QPS (全称是 Queries Per Second ,“每秒查询率” ) 3500+
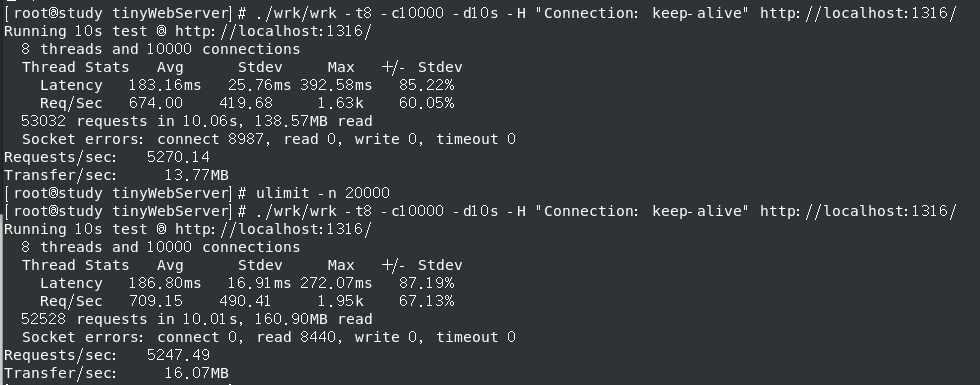
大部分connect 失败,解决加 ulimit -n 20000 短连接,同一个fd反复断开再连接,解决测试指令加 -H “Connection: keep-alive” ,减少 TCP 握手带来的开销
在第一种情况下,10,000 个连接在竞争,CPU 像疯了一样在内核态处理三次握手失败、处理重传、处理队列溢出。你的服务器主线程被这些“杂活”淹没了。
修改半连接队列长度
1 ret = listen (listenFd_, 1024 );
设置当前进程可以打开的最大文件描述符(File Descriptor, 简称 FD)的数量
TCP 连接虽然建立了,但服务器在处理请求的过程中,或者发送响应的过程中,由于压力过大,直接把连接给断开了(Connection Reset)
原理 利用极少量的线程,通过 I/O 多路复用技术(Epoll/Kqueue)来驱动成千上万个并发连接
测试 -t8 8个线程 -c10001 10000并发,HTTP连接打开 -d10s 持续10s
1 ./wrk/wrk -t8 -c10000 -d10s -H "Connection: keep-alive" http://localhost:1316/
比较 Webbench 1.5 采用 多进程同步阻塞模型 ,每一个并发连接都对应一个系统进程,这会导致严重的上下文切换开销,并在高并发下触及系统的 nproc 限制
而 wrk 采用了与我 WebServer 类似的 Reactor 模式 。它基于 Epoll + 非阻塞 I/O ,通过固定数量的线程通过事件循环驱动海量并发连接
这种设计最大限度地降低了压测工具自身的系统调用开销,使得 CPU 能够集中用于网络吞吐,从而能够更准确地测量出高性能服务器的 QPS 和长尾延迟(Tail Latency)。”
Bug HttpRequest类 1.void ParseBody_(const std::string& line); 没有根据 Content-Length 读取指定长度的字节作为 Body
实际发生的行为:
如果你的 POST Body 是 name=markparticle&age=20\r\n,它能工作
如果你的 POST Body 很长,或者中间包含换行符,或者最后没有换行符 ,这段代码就会:
找不到 lineEnd(search 失败)
或者只取到了 Body 的第一行
甚至导致解析陷入死循环或报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 case BODY: int length = stoi (header_["Content-Length" ]); if (buff.ReadableBytes () < length) { return false ; } std::string bodyStr (buff.Peek(), length) ; ParseBody_ (bodyStr); buff.Retrieve (length); state_ = FINISH; break ;
2.bool HttpRequest::parse(Buffer& buff); 即使没找到 \r\n,也截取了 line
1 2 3 4 5 6 7 8 9 10 11 12 const char * lineEnd = std::search (buff.Peek (), buff.BeginWriteConst (), CRLF, CRLF + 2 );if (lineEnd == buff.BeginWriteConst ()) { return true ; } std::string line (buff.Peek(), lineEnd) ;
3.bool HttpRequest::UserVerify(const string &name, const string &pwd, bool isLogin); RAII 与手动释放混用 修改 :既然用了 RAII,就彻底删掉最后的手动 FreeConn
逻辑错误:注册必成功
1 2 3 4 5 if (mysql_query (sql, order)) { LOG_DEBUG ( "Insert error!" ); flag = false ; } flag = true ;
修改 :把 flag=true 删了
BlockDeque类 1.template<class T> void BlockDeque<T>::push_back(const T &item) 1.template<class T> void BlockDeque<T>::push_front(const T &item) 没有判断队列的关闭状态(isClose_)
为什么必须判断“已关闭”?
无效生产 :如果 Close() 函数已经被调用(通常意味着服务器正在关闭或日志系统停止),此时继续往队列里塞数据是没有意义的,因为消费者可能已经退出,这些数据将永远留在内存中死锁/无法退出 :如果生产者线程在 condProducer_.wait(locker) 处阻塞,而此时主线程调用了 Close() 并通过 notify_all 唤醒了所有线程,这个生产者醒来后如果不检查 isClose_,它会继续尝试检查 size() >= capacity_。如果条件依然成立,它可能再次进入等待,或者直接往一个“逻辑上已关闭”的容器里写数据优雅退出 :一个健壮的并发容器应该提供一种机制,告诉生产者:“别塞了,我们要下班了”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 template <class T >void BlockDeque<T>::push_back (const T &item) { std::unique_lock<std::mutex> locker (mtx_) ; if (isClose_) { return ; } while (deq_.size () >= capacity_) { condProducer_.wait (locker); if (isClose_) { return ; } } deq_.push_back (item); condConsumer_.notify_one (); }
Warn 1.顺序不一致 1 2 3 4 5 6 7 8 9 10 11 12 In file included from ../code/server/webserver.cpp:5: ../code/server/webserver.h: In constructor ‘WebServer::WebServer(int, int, int, bool, int, const char*, const char*, const char*, int, int, bool, int, int)’: ../code/server/webserver.h:72:9: warning: ‘WebServer::port_’ will be initialized after [-Wreorder] 72 | int port_; | ^~~~~ ../code/server/webserver.h:66:10: warning: ‘bool WebServer::openLinger_’ [-Wreorder] 66 | bool openLinger_; | ^~~~~~~~~~~ ../code/server/webserver.cpp:9:1: warning: when initialized here [-Wreorder] 9 | WebServer::WebServer( | ^~~~~~~~~ make[1]: 离开目录“/home/zxc/bin/tinyWebServer/build”
虽然你在初始化列表中先写了 port_,但 C++ 实际上会先初始化 openLinger_ 。如果 port_ 的初始化依赖于 openLinger_ 的结果,就会导致 port_ 使用了一个尚未初始化的值,从而引发难以排查的 Bug
1 2 3 4 5 6 7 8 WebServer::WebServer ( int port, int trigMode, int timeoutMS, bool OptLinger, int sqlPort, const char * sqlUser, const char * sqlPwd, const char * dbName, int connPoolNum, int threadNum, bool openLog, int logLevel, int logQueSize): openLinger_ (OptLinger), timeoutMS_ (timeoutMS), isClose_ (false ), port_ (port), timer_ (new HeapTimer ()), threadpool_ (new ThreadPool (threadNum)), epoller_ (new Epoller ())
2.定义未使用 1 2 3 4 5 6 ../code/http/httprequest.cpp: In static member function ‘static bool HttpRequest::UserVerify(const string&, const string&, bool)’: ../code/http/httprequest.cpp:184:18: warning: variable ‘j’ set but not used [-Wunused-but-set-variable] 184 | unsigned int j = 0; | ^ ../code/http/httprequest.cpp:186:18: warning: variable ‘fields’ set but not used [-Wunused-but-set-variable] 186 | MYSQL_FIELD *fields = nullptr;
修改 :注释掉即可,防止后面使用
Question 最新版Web服务器项目详解 - 13 踩坑和面试题
为什么日志系统和数据库连接池需要单例模式,而线程池不需要 1. 为什么日志系统(Log)需要单例?
资源独占(文件句柄): 日志通常写入同一个物理文件。如果存在多个日志实例,多个文件指针同时操作一个文件,会导致日志内容交织、乱码 ,甚至因为争夺文件锁而崩溃。全局调用需求: 服务器的每一个角落(HttpConn、Epoller、Timer、SqlPool)都需要记录日志。如果不是单例,你必须给每一个类、每一个函数都传递一个日志对象的指针。
单例的好处: 随时随地通过 Log::Instance()->write(…) 调用,代码极其整洁。
配置统一: 全局只有一套日志级别(DEBUG/INFO)和一套刷新策略,单例确保了策略的全局一致性。
2. 为什么数据库连接池(SqlConnPool)需要单例?
资源总量控制(最重要): 数据库服务器(MySQL)允许的最大连接数是有限的(由 max_connections 配置)。
痛点: 如果不使用单例,你在 A 模块创建一个池(10个连接),在 B 模块又创建一个池(10个连接),很难统计和限制整个进程到底占用了多少数据库资源。单例的好处: 作为一个“资源管家”,全局统筹分配这固定的 N 个连接,防止连接数溢出导致数据库拒绝服务。
业务逻辑的全局性: 数据库校验(登录、注册)可能发生在不同的逻辑分支,单例保证了所有业务共用一个底层池,提高了连接的复用率。
3. 为什么线程池(ThreadPool)不需要(也不建议)单例? 在本项目中,线程池被设计为 WebServer 类的一个成员变量(通过 unique_ptr 管理),而不是单例。原因如下:
生命周期归属(Ownership):
线程池是属于 服务器实例的。它的生命周期应该随服务器的启动而创建,随服务器的关闭而销毁。
如果 WebServer 对象析构了,线程池也就没有存在的意义了。将其作为成员变量,利用 RAII 机制可以更自然地管理其生命周期。
灵活的可扩展性(多实例需求):
场景: 假设你的程序需要同时开启两个 Web 服务,一个监听 80 端口处理外网请求,一个监听 8080 端口处理内部管理。如果线程池是单例: 两个服务必须共享同一个线程池。如果 80 端口被攻击导致任务堆积,会直接拖垮 8080 端口的管理后台,导致隔离性差 。如果不是单例: 你可以为 80 端口分配一个 16 线程的池,为 8080 分配一个 2 线程的池。两个服务互不干扰,实现了资源隔离 。
调用层级明确:
线程池通常只由 WebServer 类(指挥部)调用,用来分发 OnRead、OnWrite 任务。HttpConn 或 Timer 等底层模块一般不需要直接向线程池扔任务。因此,它不需要像日志那样提供“全局访问点”。
总结对照表
模块
核心资源
为什么选单例?
为什么不选单例?
日志系统 磁盘文件
防止多实例写入冲突,方便全局调用
-
数据库连接池 DB 连接
集中管理稀缺资源,严格控制总连接数
-
线程池 CPU / 线程
-
方便资源隔离,生命周期随 Server 实例绑定
epoll 的 EPOLLONESHOT 机制 在连接初始化时,为每个连接 Socket 注册了该标志。这意味着一旦某个工作线程从 epoll_wait 拿到该 Socket 并开始处理,内核就会自动禁止该 Socket 产生后续事件,从而避免了多个线程同时操作同一个请求的竞态条件
关键点在于重装(Rearm)逻辑 :当工作线程处理完业务逻辑后,调用 epoll_ctl 配合 EPOLL_CTL_MOD 来重置该 Socket。在重置时,利用预设的 connEvent_ 掩码(其中已包含 EPOLLONESHOT) 配合当前的读写需求进行按位或操作
这种‘每次修改状态都重新设置 ONESHOT 的做法,既实现了线程安全,又保证了 Reactor 模式下任务调度的连贯性。”
框架
补充 1.补充 Config 类 Mysql 配置暂定不可修改
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #ifndef CONFIG_H #define CONFIG_H #include "../server/webserver.h" using namespace std;class Config { public : Config (); ~Config (){}; void parse_arg (int argc, char *argv[]) int port_; int trigMode_; int timeoutMS_; bool OptLinger_; int sqlPort_; const char * sqlUser_; const char * sqlPwd_; const char * dbName_; int sqlNum_; int threadNum_; bool openLog_; int logLevel_; int logQueSize_; }; #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #include "config.h" Config::Config (){ port_ = 1316 ; trigMode_ = 3 ; timeoutMS_ = 60000 ; OptLinger_ = false ; sqlPort_ = 3306 ; sqlUser_ = "root" ; sqlPwd_ = "centos" ; dbName_ = "tinyWebServer" ; sqlNum_ = 12 ; threadNum_ = 6 ; openLog_ = true ; logLevel_ = 1 ; logQueSize_ = 1024 ; } void Config::parse_arg (int argc, char *argv[]) int opt; const char *str = "p:m:o:s:t:l:e:q:" ; while ((opt = getopt (argc, argv, str)) != -1 ) { switch (opt) { case 'p' : { port_ = atoi (optarg); break ; } case 'm' : { trigMode_ = atoi (optarg); break ; } case 'o' : { OptLinger_ = (atoi (optarg)==1 ); break ; } case 's' : { sqlNum_ = atoi (optarg); break ; } case 't' : { threadNum_ = atoi (optarg); break ; } case 'l' : { openLog_ = (atoi (optarg)==1 ); break ; } case 'e' : { logLevel_ = atoi (optarg); break ; } case 'q' : { logQueSize_ = atoi (optarg); break ; } default : break ; } } }
修改 main.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <unistd.h> #include "server/webserver.h" #include "config/config.h" int main (int argc, char *argv[]) Config config; config.parse_arg (argc, argv); WebServer server ( config.port_, config.trigMode_, config.timeoutMS_, config.OptLinger_, config.sqlPort_, config.sqlUser_, config.sqlPwd_, config.dbName_, config.sqlNum_, config.threadNum_, config.openLog_, config.logLevel_, config.logQueSize_) server.Start (); }
修改Makefile
1 2 3 OBJS = ../code/log/*.cpp ../code/pool/*.cpp ../code/timer/*.cpp \ ../code/http/*.cpp ../code/server/*.cpp \ ../code/buffer/*.cpp ../code/main.cpp ../code/config/*.cpp
个性化运行 1 ./bin/server [-p port_] [-m trigMode_] [-o OptLinger_] [-s sqlNum_] [-t threadNum_] [-l openLog_] [-e logLevel_] [-q logQueSize_]
以上参数不是非必须,不用全部使用,根据个人情况搭配选用即可
-p,自定义端口号
-m,listenfd和connfd的模式组合,默认使用ET + ET
0,表示使用LT + LT
1,表示使用LT + ET
2,表示使用ET + LT
3,表示使用ET + ET
-o,优雅关闭连接,默认不使用
-s,数据库连接数量
-t,线程数量
-l,关闭日志,默认打开
-e,日志等级,默认1
0,debug
1,info
2,warn
3,error
-q,日志队列大小,大于0为异步,小于等于0为同步
最终项目 tiny-star3/tinyWebServer: tinyWebServer